

Build 360° view of customer or citizen
Accurate entity resolution implemented either natively or integrated into current MDM solutions.
Accurate entity resolution forms the basis for generating a 360° view of person.
Entity resolution refers to the process of identifying the full set of records from data sources that correspond to the same real-world entity. Once entity resolution is completed, it is a relatively straight forward process to assemble the 360° view of person from the relevant data associated with the corresponding data source records.
Currently entity resolution is typically based on using traditional Master Data Management (MDM) solutions. But traditional MDM solutions rarely measure matching accuracy. This is particularly signficant because MDM record matching tends to perform poorly at detecting hard-to-find matches, so it is prone to having false negative errors.
But help is at hand. By integrating Factil's data matching and matching evaluation technologies with existing MDM solutions we can get a blended solution that:
- Formally measures entity resolution accuracy
- Detects a higher proportion of hard-to-find record matches
- Automates clerical review decisions that would otherwise be done manually
Let's examine this idea more closely ...
Master Data Management integration
According to leading industry analyst Gartner, Master Data Management (MDM) solutions are enterprise software products that support the management of one or more master data domains — such as customer, citizen, product, “thing,” asset, person or party, and supplier — via range of technologies and capabilities to sustain the concept of a trusted “golden record” for master data.
MDM solutions:
- Support the global identification, linking and synchronization of master data across heterogeneous data sources through reconciliation.
- Create and manage a central, persisted system or index of record for master data.
- Support registry, consolidation, centralized and coexistence MDM hub implementation styles.
- Enable generation and delivery of a trusted version of one or more data domains to all stakeholders, in support of various business initiatives.
- Support ongoing master data stewardship and governance requirements through workflowbased monitoring and corrective-action techniques.
- Are agnostic to the business application landscape in which they reside; that is, they are “application neutral”.
MDM solutions are fundamentally based on building a master list of golden records and only comparing new records against this list. The attributes of a golden record are established by applying survivorship rules to the atttributes of the match group records associated with the golden record. The comparison of new records to golden records is based on previously agreed business rules, which tend to take a limited number of fields into consideration.
This approach to record matching and entity resolution is computationally efficient, but tends to perform poorly at detecting hard-to-find matches. As a result, it is prone to having a high proportion of false negative errors. But this problem is rarely noticed because little attention is paid to measuring the record matching accuracy in terms of Precision and Recall.
High-level MDM integration architecture
Factil's advanced record matching and matching evaluation technologies can be readily integrated into an MDM solution.
The high-level MDM integration architecture is shown below:
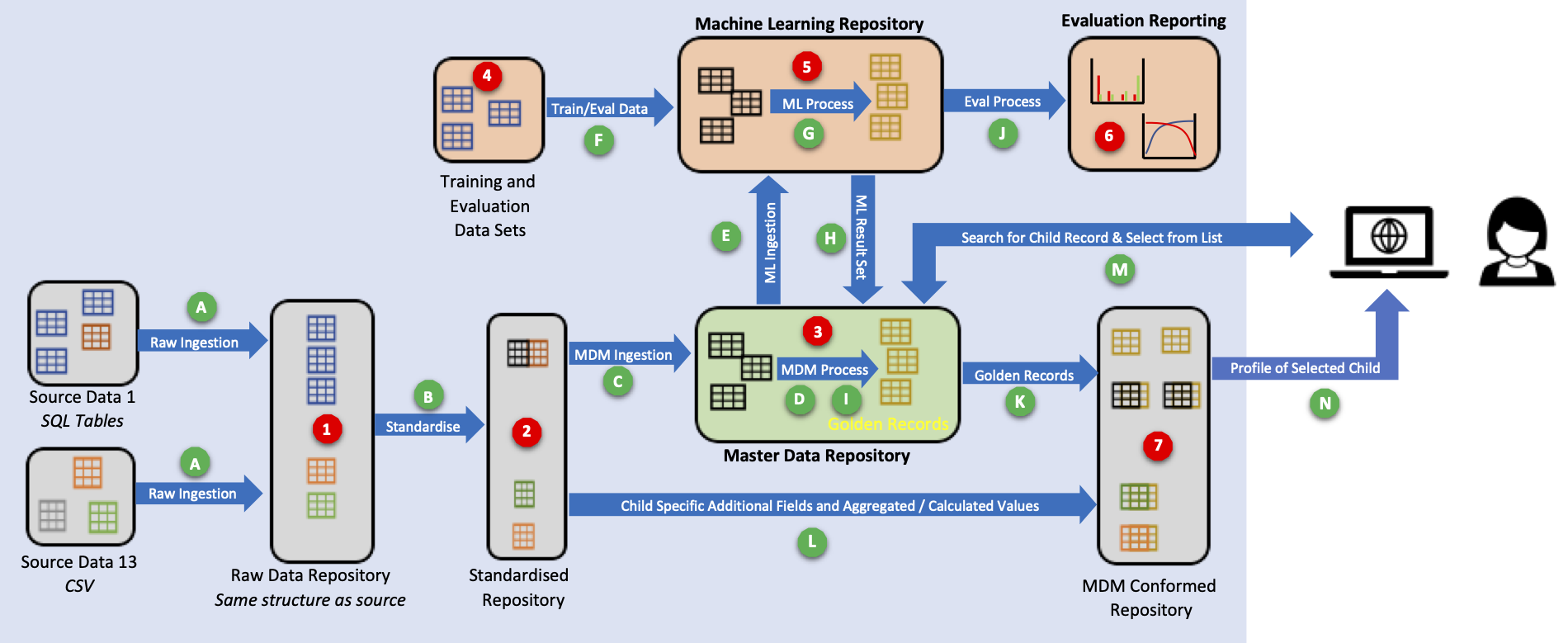
The lower half of the diagram is essentially a standard MDM data integration architecture. The upper half of the diagram shows the interconnection between the MDM system and Factil's data matching and matching evaluation techologies.
Data Layers and respositories
Data resides in a number of areas and respositories in this architecture as follows:
- Raw Data Repository: Holds source data in the raw form where the structure of the relevant source tables or views are replicated as SQL tables in the Raw Data repository.
- Standardised Repository: Based on the appended data held in the Raw Data repository, the records across the raw tables are restructured into standard tables for each domain.
- Master Data Repository: The MDM repository accommodates relevant source records ingested by the MDM solution as well as the MDM golden records generated by the MDM solution.
- Training and Evaluation Data Sets: Comprises of a set of certainly matched records, and definitely not matched records (as determined by a person).
- Machine Learning Repository The ML repository contains a complete set of child records from the MDM repository in order to undertake its own matching algorithms.
- Evaluation Reporting: Detailed reports and charts of the data matching accuracy of the MDM and ML algorithms.
- MDM Conformed Repository: The MDM conformed repository contains relevant golden records required for reporting and analysis, mapping of the business key in the source records, conformed transactional records.
Key data flows
The key data flows through this architecture are as follows:
- Raw Ingestion: Raw ingestion is the process of extracting new, changed or deleted records to populate the raw data repository.
- Standardise: Standardise process applies standard formatting to source data columns such as date string into dates and concatenate address fields.
- MDM Ingestion: The fields required for matching and/or survivorship are passed from the Standardised Repository.
- MDM Process (1): May initially enrich the records (e.g. allocate DPID for the addresses) and performs the hierarchy of rule based matching rules to identify the match groups.
- ML Ingestion Bulk extract of the records / fields required for the Machine Learning process.
- Training Data: The set of child records that have been confirmed as a match or not a match.
- ML Process: Applies the ML logic to the records to identify the match groupings / mapping table.
- ML Result Set: The ML matched records mapping table (includes the confidence match / status).
- MDM Process (2): Compares the MDM mappings table to the ML mappings table, applies the survivorship rules for the match groupings to generate the Golden Records. The suspect matches are managed by the Data Steward using the standard MDM interface.
- Evaluation Process: Evaluate data matching accuracy of the MDM and ML algorithms in terms of Precision, Recall and F-score against a reference Evaluation set.
- Golden Records: The Golden Records are copied to the MDM Conformed Repository.
- Additional Fields and Calculated Values: The additional person fields and calculated values are copied to the MDM Conformed Repository.
- Search for Person Record & Select from List: The end users of the solution will be able to query the solution using whatever details they have; the result set is sent back to the user who makes a selection.
- Profile of Selected Person The selected record (Golden Record ID) from “L” above is used to generate the full profile of the person.
By integrating Factil's data matching and matching evaluation technologies with existing MDM solutions we can get a blended solution that formally measures entity resolution accuracy, detects a higher proportion of hard-to-find record matches, and automates clerical review decisions that would otherwise be done manually.
Formally measure entity resolution accuracy
We introduced the concepts of precision, recall and f-score for measuring record matching accuracy on the evaluation page.
With entity resolution accuracy we are concerned with the false positive and false negative errors arising from classifying two records as being in the same entity or not.
With this definition, the concepts of precision, recall and f-score to can be applied to entity resolution. For entity resolution, the record pair "score" is either 0 (the two records are classified into different entities) or 1 (the two records are classified into the same entity). In contrast, for record matching, the record pair score is a numeric value between 0 and 1.
Because of this difference, the labelled pairs distribution for entity resolution only has columns in the first and last quantile. Similarly, the Precision/Recall graph has two straight lines because there are no intermediate values.
Here are the labelled pair distribution and precision/recall charts from a real-world example.
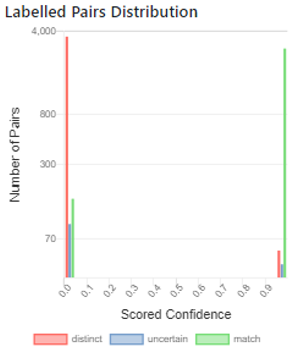
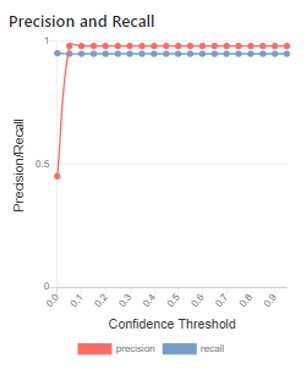
Once again, these charts can be used to highlight the occurances of both false positive (high scored distinct pairs) and false negative (low scored match pairs) for entity resolution. For these results the maximum f-score is 96.87%, which gives us a single figure to measure the entity resolution accuracy.
Just as importantly, measuring entity resolution accuracy is gives us a starting point for improving entity resolution accuracy.
Detect hard-to-find record matches
In order to cover a wide range of use cases, Factil has developed two advanced data matching algorithms for matching person, relationship and location information. Both algorithms are based comparing record pairs to calculate a comparison score.
- Probabilistic Matching: the comparison score of a pair of records is based on the estimated probability that a pair of records represent the same entity. Probabilistic matching is an unsupervised machine learning technique because the probability factors used in the calcalation are derived directly from a statistical analysis of the frequencies of attribute values.
- Logistic Regression: the comparison score of a pair of records is based the similarity of a pair of records. Logistic Regression is a supervised machine learning technique because the weights used in the calcuation are derived by a mathematical optimisation algorithm against a Training Set of known labelled record pairs.
Both of these algorithms perform well at detecting true matches that are missed by traditional data matching techniques. Our algorithms have a high recall compared to traditional data matching techniques, while maintaining equal or superior precision.
These algorithms are described in more detail on the Data Matching page.
Automate clerical review decisions
It is common in the traditional MDM process to classify new records as either confident matches, suspect matches or unique records compared to the existing master records. Suspect matches are passed on to a data steward for clerical review to determine whether they should be manually attached to a existing match group, or added as a new unique record. In a domain where there are significant data quality issues, or where there is a natural variation of identifying attributes, there is potentially a large number of suspect matches requiring manual review.
By integrating Factil's ML data matching and matching evaluation technologies with existing MDM solutions we can get an automated "second opinion" about classification of new records.
- The ML record matching algorithms are used to calculate the similarity score of a new record with the existing master records.
- Based on the measured accuracy of the ML record matching algorithms, optimal thresholds can be set for the classification of new records as confident matches, suspect matches and unique records.
- Reclassify the new records according to the combined view of MDM and ML algorithms. Intuitively: if both systems agree, then there is no change; if MDM and ML have opposite views then the record should be suspect; but if the MDM classifies a record as suspect, then the ML classification should be used. The final classification matrix could look as follows:
Machine Learning Confident Suspect Unique Confident Confident Suspect Suspect MDM Suspect Confident Suspect Unique Unique Suspect Suspect Unique
Our experience has been that MDM matching algorithms tend to have good precision but poor recall, which means that a number of matches are either missed or treated as suspect. With the approach outlined here, MDM suspect/ML confident records will be automatically classified which will reduce the rate of clerical review decisions.