

Fact Based Modeling and Data Vault
This article introduces and presents the strong conceptual overlap between Fact-Based Modeling and the Data Vault data warehouse modeling, and the practical results that can be achieved for Data Vault schema generation from a fact-based model.
Fact-Based Modeling is a semantically-rich conceptual approach for modeling, querying and transforming information. It is based on the following principles:
- All facts of interest are conceptually represented in terms of attribute-free structures known as fact types.
- Conceptual models are developed from concrete examples of the required information.
- Conceptual models are verbalised in a controlled natural language.
In this article we will be concerned with two fact-based modeling approaches: Object-Role Modeling (ORM) provides both a textual modeling language and an equivalent graphical modeling language, and Factil's Fact-based Information Modeling Language (FIML). A hallmark of FIML it is that concise and precise structured nearly-natural language for conceptual modeling that is readily understood and verified by domain experts. This article includes a short introduction to FIML. A more comprehensive introduction can be found in the Introduction to FIML article.
Data Vault is a relational data modeling approach that is optimised for data warehouses. It is distinguished from Third Normal Form (3NF) modeling which is suited for operational systems and Star Schema (Dimensional) modeling which works well for Data Marts.
The underlying premise behind Data Vault modeling is that data associated with business keys, relationships and associated information is decomposed in a specific way so to provide flexibility, adaptability and agility in a data warehouse context.
At a high-level we see Data Vault as a partially decomposed modelling approach, compared to Fact-Based Modeling which is fully decomposed.
Fact-Based Modeling tools have well establishing composition rules for generating a 3NF schema from a fact-based model. This article introduces composition rules for generating a Data Vault schema from a fact-based model.
This article provides an overview of the Data Vault and subset of the FIML language concerned with Data Vault schema generation, and a summary with examples of Data Vault schema generation from fact-based models. Links to further resources can be found at the end of the article.
Data Vault Overview
The underlying premise behind Data Vault is the notion of Unified Decomposition.
Data Vault breaks things into their component parts for flexibility, adaptability, agility, and generally to facilitate the capture of things that are either interpreted in different ways or changing independently of each other – to decompose.
At the same time, Data Vault moves to a common standard view of unified concepts – to unify.
Data Vault models the component parts of a core business concept as an ensemble consisting of:
Hub, which holds the business key but no descriptive data. There is a single hub in each ensemble. A hub can only be connected to links and satellites within its ensemble.
Links, which represent the Business Relationships, but no descriptive data. A link can have binary or n-ary connections to hubs. Links can be connected to satellites.
Satellites contain all context, descriptive data and history. A satellite must have only one connection, which can be to a hub or link.
Diagrammatically, the information that would normally be housed in a single 3NF table or dimensional star schema is represented in multiple tables in a Data Vault ensemble.
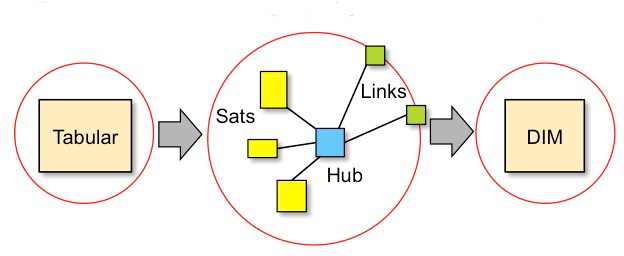
In this and the following diagrams, hubs are shown as blue boxes, links as green boxes and satellites as yellow boxes. The ensemble is shown as a red circle. There is one hub per ensemble. Links are shown on the edge of an ensemble because they are linked to other hubs.
In Data Vault the hubs and links form the backbone of the schema.
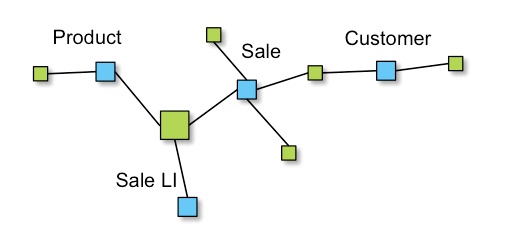
The purpose of hubs and links is to identify the business concepts and the relationships between business concepts. The physical schema of hubs and links is tightly controlled.
A hub consists of:
- Hub Surrogate Key (primary key)
- Business Key (one or more fields)
- Creation date/time field
- Record source field
A link consists of:
- Link Surrogate Key (primary key)
- Two or more foreign keys to hubs
- Creation date/time field
- Record source field
The physical schema of satellites is more flexible:
- Single foreign key to either link or hub
- Creation date/time field
- One or more data fields
- Record source field
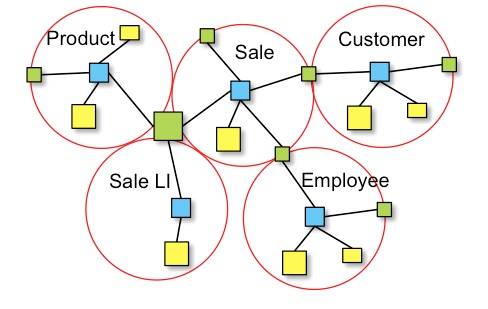
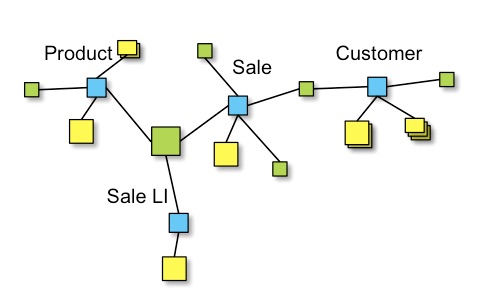
A full Data Vault model might look like this:
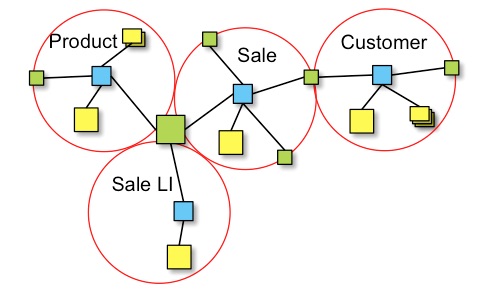
Link relationships can be read as a phase. In this example:
Product was sold with Sale according to Sale LIwhere the naming of Product, Sale and Sale LI is given by their respective business keys.
Architectural Advantages of Data Vault for Data Warehouse
A Data Warehouse concerned with enterprise-wide data integration, data alignment and reconciliation, providing a historical record of changed data, and audit trail of the changes.
As we explain below, Data Vault has a number of important advantages for data modeling in the data warehouse including
- Handling change flexibility
- Managing history efficiently
- Data loading efficiencies
Taken together the agility, flexibility and efficiency advantages of Data Vault make it a compelling data modeling approach for the Data Warehouse.
Handling Change Flexibly
One of the key architectural benefits of Data Vault is their ability to handle change flexibly compared to 3NF and Dimensional modeling approaches.
Backbone nodes are never updated or destroyed
Once hub and link records are created they are never updated or destroyed. This means there is never any requirement for cascading deletes within a Data Vault, and there is never any data consistency issues within Data Vault for failure to carry out implicit cascading deletes.
New concepts added incrementally
When a new concept is added and linked to existing concepts, there is never need to add new keys to existing data, all required keys are already available for any allowed configuration.
This example shows the addition of the Employee ensemble. Because of the structural rules of Data Vault this new ensemble can be added with requiring any change to the existing schema.
Attribute value changes
Descriptive attribute value changes are localised to adding a new record to a small satellite table. There is never the need to change any records in the Data Vault backbone.
In contrast in a 3NF or Dimensional schema this would require a record update, often bracketed by a transactional lock.
New attribute changes
A new attribute change is localised to a schema changes to a small satellite table or addition of a new satellite table. There is no impact on hubs, links or other satellites
In contrast in a 3NF or Dimensional schema this would require a large table schema change.
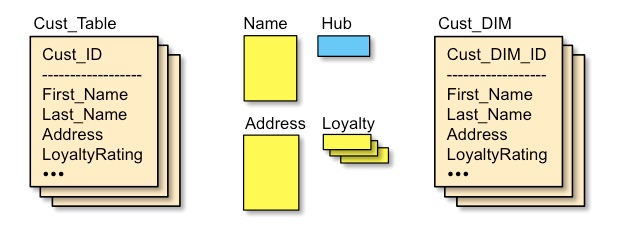
In the example below, suppose a new Loyalty Rating attribute is to be added. In 3NF or Dimensional schemas this would cause a major change to the Cust_Table or Cust_DIM tables. But within Data Vault this could be accommodated with either a new satellite or a change to a small satellite table containing related data.
Managing History Efficiently
A second key architectural benefit of Data Vault is its ability to manage history efficiently compared to 3NF and Dimensional modeling approaches.
Hubs and Links form the backbone of a Data Vault schema. Records in Hub and Link tables can be created and read, but they are not updated or deleted. Descriptive data which can change of time is held in Satellite tables. Descriptive attribute value changes are localised to adding a new record to a small satellite table. Existing Satellite records are kept so as to maintain a historical record of the values of this descriptive data. The current value of the descriptive data can be found by selecting the most recent record for a particular Hub or Link foreign key.
Some Data Vault implementations maintain a current flag to improve the efficiency for making the search for the most recent record for a particular Hub or Link foreign key. When this approach is taken there is an additional cost when inserting a new record into a Satellite to check whether there is an existing the record with this foreign key, and updating the record to switch off this flag before the new record is added.
Apart from the exception for maintaining current flags, records in the Data Vault schema are not updated or deleted. Updates and deletes are expensive operations and are common in 3NF and Dimensional models.
Data Loading efficiencies
Data loading is simplified because load dependencies are greatly reduced. The standard order for loading records in Data Vault is as follows:
- Load new Hubs. All new Hubs can be loaded in parallel because there are no key dependencies.
- Load new Links and Hub Satellite updates. All new Links and Hub Satellite updates can be loaded in parallel because they are only dependent on Hub foreign keys.
- Load Link Satellite updates. All Link Satellite updates can be loaded in parallel because they are only dependent on Link foreign keys.
In comparison data loading in 3NF and Dimensional schemas can have complex ordering dependencies and may require transactional bracketing in order to maintain database integrity.
Fact-Based Modeling and FIML
One of the defining characteristics of Fact-Based Modeling is that they are "attribute-free". Fact-Based models do not presuppose the entity/attribute mapping underpinning Entity-Relation Modeling (ER), Unified Modeling Language (UML) or the majority of other modeling approaches.
Within in Fact-Based Modeling there is no division between entities and attributes -- they are modeled in the same way. Whereas the traditional model approaches treat establishing the distinction between entities and attributes as a step toward implementation (i.e. moving from the conceptual to the logical to the physical model), Fact-Based Modeling focuses on declaring the relationships, cardinalities and constraints between the concepts. Fact-based models create a semantically rich conceptual model of domain of discourse. The physical schemas that then be obtained directly by applying composition rules to the conceptual model.
Different relational forms, 3NF, Data Vault and Dimensional, can be generated from the one conceptual model by applying different composition rules.
In order to describe the composition rules for Data Vault, we will give a shortened introduction to FIML. A more comprehensive introduction can be found href="/resources/whitepapers/introduction-to-fiml/">Introduction to FIML article.
Fact-based Information Modeling Language (FIML)
The Fact-based Information Modeling Language (FIML) is a language for constructing and querying fact-based information models.
A FIML model is composed of the following kinds of statements:
- Object Type definitions, each designated by a name (which may be multiple words, conventionally using initial upper-case). An object type is either:
- a value type, which is the type of a single value (e.g., number, name, date, etc)
- an entity type, which identifies a class of things of interest (e.g., country, product, asset)
- a named fact type, which is a named relationship (e.g., employment, production forecast)
- Fact Types that declare the relationship between object types or a (boolean) characteristic of a single object type. A fact type is designated by one or more readings which gives a verbal description of the object types' relationship.
- Constraints that state conditions which restrict the allowed object instances and facts in the model.
- Units that are used to automate value conversion.
- Instances of object types and facts conforming to fact types, which are used as examples, reference data, or for test scenarios.
- Queries which can be asked in the modeling language, and return either true/false or a result set answer. A query can also be projected as a Derived Fact Type, akin to a view.
FIML is written as series of controlled natural language statements. A number of key phrases have special meaning in the language but the majority of the statements are written in close to conventional natural language with a minimum of markup or special typography. This facilitates communication over conventional channels and with untrained people.
Here is a short summary of the syntax of value types, entity types and fact types FIML which is relevant for discussing Data Vault composition.
Value Type
A value type identifies a concept in the model with a single value (e.g., number, name, date, etc). A new value type is based on a parent value type with possible range restrictions and parameters. A value type is introduced with an "is written as" statement:
each VALUE_TYPE_ID is written as a BASE_VALUE_TYPE_ID(PARAMS)
For example:
each Quantity is written as an Unsigned Integer(32);
FIML itself has no built-in value types (you can use whatever names you like), but certain types are special when mapping to database or programming technologies, including String, Signed and Unsigned Integer, Real, Boolean, Date. Each value instance is identified by its canonical written form (so Real 2.00 is the same value as Real 2).
Value Type Restriction
Value type constraints are introduced inside curly brackets, and are defined by a list of values or value ranges (including ranges with either end open), introduced with a "restricted to" word sequence:
each VALUE_TYPE_ID is written as a BASE_VALUE_TYPE_ID restricted to { RESTRICTION }
For example:
each Season is written as a String restricted to {'Autumn', 'Spring', 'Summer', 'Winter'};Entity Type
An entity type identifies a named concept in the model (e.g., country, product, asset). An entity type is introduced with an "is identified by" statement. Entity type statements have a short form and a long form. The short form is introduced by "its" and provides implied readings for the entity and its name:
each ENTITY_TYPE_ID is identified by its OBJECT_TYPE_ID
For example:
each Product is identified by its Name;
In the long form, multiple identifying roles can be defined and the fact type readings associated with the roles are stated explicitly.
Subtyping
An entity type may be declared to be a subtype of one or more supertype entity types. A subtype inherits all the characteristics of its supertype. Subtyping is introduced with a "is a kind of" word sequence:
each ENTITY_TYPE_ID is a kind of SUPERTYPE_ENTITY_TYPE_ID
For example:
each Person is a kind of Party
Fact Type
A fact types declares the relationship between two or more object types or a boolean property of a single object type. A fact type is designated by one or more readings which gives a verbal description of the relationship between roles taken by the object types in the fact type. (Object roles will be explained below.) A binary fact type is relationship between two objects, written with a connecting verb(s).
OBJECT_TYPE_ROLE verb OBJECT_TYPE_ROLE
For example:
Customer raises Order
A ternary or greater fact type is a relationship between three or more objects, and will typically be written with a verb between the first two objects and prepositions between the later objects:
OBJECT_TYPE_ROLE verb OBJECT_TYPE_ROLE preposition OBJECT_TYPE_ROLE ...
For example:
Person plays Sport for Country
A unary fact type declares a boolean property of a single object type.
OBJECT_TYPE_ROLE verb
For example:
Person is deceased
Multiple readings and quantifiers
For binary and greater fact types, multiple readings can be given for the different object role orderings to denote the natural way of expressing the relationship in different contexts.
The final object role in a fact type may be preceded by a quantifier to a constraint to the cardinality of the final object role for a given set of all but the last object role. Valid quantifiers include:
one
exactly QUANTITY
at least QUANTITY
at most QUANTITY
at least QUANTITY and at most QUANTITY
from QUANTITY to QUANTITY
where QUANTITY can one one or a number.
Here is an example of multiple readings for a fact type concerned with oil supply:
Refinery in Supply Period will make Product in one Quantity, Refinery will make Product in Supply Period in Quantity, Refinery will make Quantity of Product in Supply Period;
Named Fact Type
A fact type (including its multiple readings) may be named so it can be used as an object type in the same way as a value or entity type. Each instance of that fact type is regarded as an object, so we say the fact type is objectified. A named fact type is introduced by the "is where" key phrase:
each NAMED_FACT_TYPE_ID is where FACT_TYPE
For example:
each Production Forecast is where Refinery in Supply Period will make Product in one Quantity, Refinery will make Product in Supply Period in Quantity, Refinery will make Quantity of Product in Supply Period;
Named Roles in Fact Types
Each fact type definition includes roles, each one played by one object type. An object type may be appear more than once in the same fact type, representing different roles in the relationship. For example, the Party object type appears twice in a Related Party relationship. To distinguish them in natural language they might be known as, say, the First Party and the Second Party. FIML offers several ways of indicating the different roles for the same object type in a fact type: as a named role, as an adjectival role, or by subscripting.
A named object role is introduced by a "( as ... )" key phrase:
OBJECT_TYPE_ID ( as OBJECT_TYPE_ROLE )
For example:
Celebration was organised by one Organiser, Person (as Organiser) organised Celebration;
An adjectival object role is introduced by a hyphenated adjective either before or after the object type id:
adjective- OBJECT_TYPE_ID
OBJECT_TYPE_ID -adjective
Both forms are allowed in FIML to allow for languages and customs of having the adjective before or after the noun in an expression.
The first instance of an object type role in a fact type can be a object type id (i.e. the role is implicitly named), but the second and subsequent instances of an object type must take a named role to avoid ambiguity. Each reading of a fact type has the same role naming for all its object roles.
For example, here are two readings of a fact type where the role of the first instance of Product is implicitly named, and the second instance is adjectivally named:
Product may be substituted by alternate-Product in Season, alternate-Product is an acceptable substitute for Product in Season
FIML code and ORM diagram
To give a more complete example, here is the FIML code and equivalent ORM diagram for a data model concerned with oil supply production and delivery planning.
Here is the description of the model:
A model of the supply and demand for refined oil. A populated database can be used to optimise profitability by minimising transport costs, maximise supply by allowing substitution of compatible products (with compatibility depending on season) and also to predict shortages.
Here is the the full FIML for this model:
each Cost is written as Money;
each Month Nr is written as Signed Integer(32);
each Product Name is written as String;
each Quantity is written as Unsigned Integer(32);
each Refinery Name is written as String(80);
each Region Name is written as String;
each Season is written as String(6) restricted to {'Autumn', 'Spring', 'Summer', 'Winter'};
each Transport Method is written as String restricted to {'Rail', 'Road', 'Sea'};
each Year Nr is written as Signed Integer(32);
each Month [static] is identified by its Nr restricted to {1..12};
Month is in one Season;
each Product is independent identified by its Name;
each Refinery is independent identified by its Name;
each Region is independent identified by its Name;
each Transport Route is where
Transport Method transportation is available from Refinery to Region,
Transport Method transportation is available to Region from Refinery;
Transport Route incurs at most one Cost per kl;
each Year is identified by its Nr;
each Acceptable Substitution is where
Product may be substituted by alternate-Product in Season [acyclic, intransitive],
alternate-Product is an acceptable substitute for Product in Season;
each Supply Period [separate, static] is identified by Year and Month where
Supply Period is in one Year,
Supply Period is in one Month;
each Production Forecast is where
Refinery in Supply Period will make Product in one Quantity,
Refinery will make Product in Supply Period in Quantity,
Refinery will make Quantity of Product in Supply Period;
Production Forecast predicts at most one Cost;
each Regional Demand is where
Region in Supply Period will need Product in one Quantity,
Region will need Product in Supply Period in Quantity,
Region will need Quantity of Product in Supply Period;FIML and ORM are closely related Fact-Based Modeling languages. Almost every concept in a FIML model can be represented in a ORM diagram and vice versa. We will use an ORM diagram to help illustrate the strong conceptual overlap between Fact-Based Modeling and the Data Vault modeling.
In the equivalent ORM diagram for this example you can see that the main business concepts (Refinery, Region and Product) are represented as individual nodes with associated naming (their business keys). The business relationships (named as Production Forecast, Transport Route and Region Demand) are represented as nodes with an internal box structure identifying the elements of the relationship, and a reading of the relationship where the ellipsis (...) in the reading correspond to the object roles of the relationship. Object roles of a relationship can be business concepts or associated data. The mauve annotations in the diagram indicate uniqueness constraints and mandatory constraints on the fact types, and an acyclic, intransitive constraint on Product roles of the the Acceptable Substitution fact type.
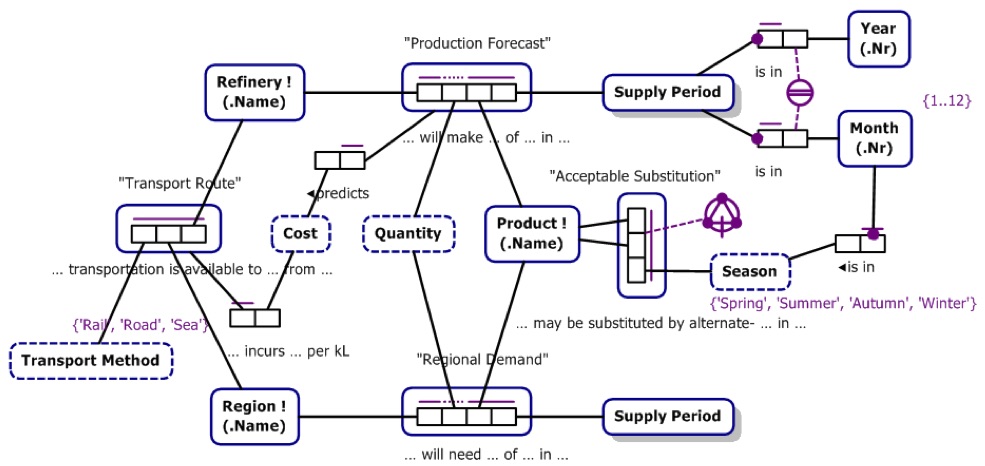
We have shown the ORM diagram to give a graphical way of visualising how the fully decomposed ORM diagram could be mapped to a Data Vault schema. In practice, Factil's toolset allows a FIML model to be directly compiled and generated as an Data Vault SQL schema.
Data Vault schema generation
The operation of generating a Data Vault schema from a Fact-Based Model is a composition operation, where there are composition rules to absorb related entities into tables to obtain a schema. In the sections below, we outline these set of rules for each modeling pattern.
FIML allows annotations embedded in square brackets "[ ... ]" to be attached to FIML statements to provide guidance in schema generation and to supplement standard mapping rules.
Data Vault Schema Generation
To assist with Data Vault schema generation, entity types can be annotated as follows.
| Annotation | Meaning |
| [ satellite <name> ] | This entity type should be kept in a satellite table with name <name> with other entities tagged with the same satellite name |
| [separate] | This entity type should be generated as a separate table |
| [static] | This entity type would be a reference or dimension table |
To obtain a Data Vault Schema from a Fact-Based Model the following generation procedure is performed:
Data Vault High-Level Generation Procedure:- Generate a normal 3NF schema, using the 3NF Generation Procedure, taking note of [separate] annotation.
- Partition these tables into reference/dimension, hub and link groups. Links have an identifier consisting of references to two or more other tables.
- For each hub and link table, create satellite tables to store all functionally related data values
- Add timestamps and data source identifier columns
- Emit all hub, link and satellite tables, omitting reference tables
And here is the 3NF generation procedure:
3NF High-Level Generation Procedure:- Assign each object type a tentative table/not-table status based on several heuristics:
- A n-ary fact type must always be a table
- An independent or separate object type must be a table
- For each object type that still has tentative status, look at the status of all object types which play a role in its identifier to see if a decision can now be made:
- A unary fact type is always absorbed
- An entity type whose identifier is a single table and has no other functional references to it can be absorbed
- An entity type that has more than one possible absorption path but has other functional dependencies, it must be a table
- Some entity types can be fully absorbed in more than one place (e.g. Address)
- One-to-one references can sometimes be flipped in absorption direction
- Repeat until all possible decisions have been made, then make remaining tentative decisions final.
Using the CQL compiler to generate Data Vault schema
CQL was originally developed as part of the Active Facts project principally developed by Clifford Heath. This project includes the CQL compiler afgen, which reads a CQL or ORM data model and can generate any of a range of application and systems development outputs, including a Data Vault SQL schema.
For the Oil Supply example, the generated Data Vault Schema looks like:
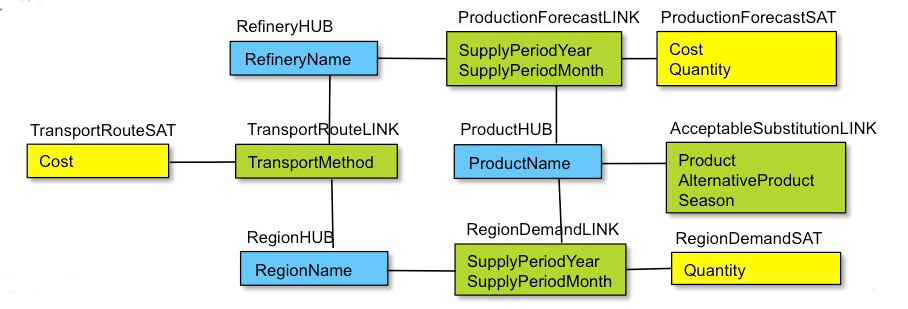
In this example, no annotations are required to obtain a Data Vault schema backbone.
The CQL compiler command line to generate Data Vault SQL schema is:
afgen --transform/datavault --sql/server OilSupply.cql > OilSupply-DV.sql
This file can be directly incorporated into your standard data modeling process, including being read into standard ER modeling tools. Here is an ER diagram generated by such a tool directly from the OilSupply Data Vault SQL file:
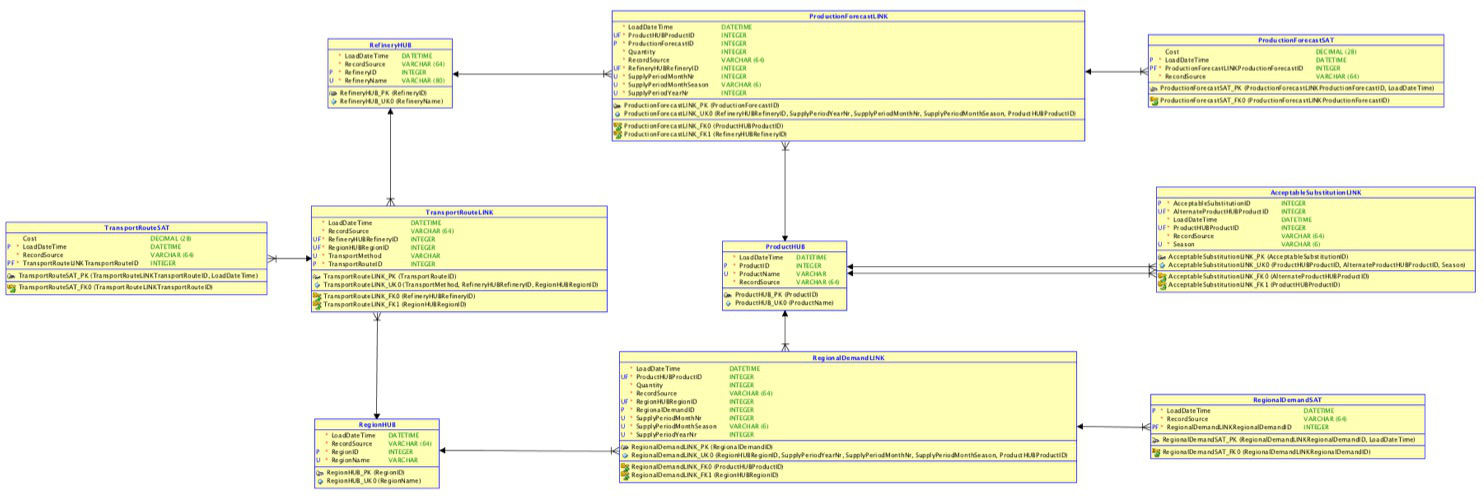
Although the font size of this picture is probably too small to see in detail, it is clear from the diagram structure that all tables, attributes and their types, primary and foreign keys and associated constraints have been defined in this Data Vault SQL file.
Full details about downloading and using the open source FIML complier can be found in Introduction to FIML.
Conclusion and Further Resources
This article has introduced the strong conceptual overlap between Fact-Based Modeling and the Data Vault data warehouse modeling, and the practical results that can be achieved for Data Vault schema generation from a fact-based model.
Both Data Vault and Fact-Based Modeling are based on the notion of decomposition of the data model. Data Vault's decomposition is partial, the with guidelines for creating a Data Vault model directed by the practicalities of implementing a flexible, adaptable and agile data warehouse.
Fact-based models are fully decomposed but semantically rich in terms of the relationships, cardinality and constraints between all concepts. The richness of Fact-Based Modeling allows the definition of composition rules that can create high-quality consistent 3NF and Data Vault schemas.
These composition rules have been implemented and released in the open source FIML compiler.
References
[1] Halpin, T., 2015, Object-Role Modeling Fundamentals, Technics Publications.
[2] Hultgren, H., 2012, Modeling the Agile Data Warehouse with Data Vault, New Hamilton.
[3] Linstedt, D., 2010. Super Charge your Data Warehouse. Dan Linstedt.